Připravené SQL dotazy. Jednoduché dotazy pro získávání dat pomocí SQL. Vyberte všechny sloupce
Takže v databázi fóra jsou tři tabulky:
· uživatelé (uživatelé);
· témata (témata);
· příspěvky (zprávy).
Musíte se podívat, jaká data obsahují. V SQL na to existuje operátor VYBRAT. Syntaxe pro jeho použití je následující:
SELECT what_select FROM where_select;
Místo „what_select“ musíte zadat buď název sloupce, jehož hodnoty chcete zobrazit, nebo názvy několika sloupců oddělených čárkami, nebo symbol hvězdičky (*), což znamená výběr všech sloupců tabulky. Místo „where_select“ byste měli zadat název tabulky.
Nejprve se podívejme na všechny sloupce z tabulky uživatelů:
SELECT * FROM uživatelů;
Toto jsou všechna data, která byla zadána do tabulky.
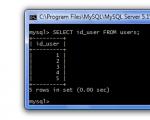
Předpokládejme, že se stačí podívat na sloupec id_user (protože k naplnění tabulky témat potřebujete vědět, kteří id_users jsou v tabulce uživatelů). Chcete-li to provést, zadejte v dotazu název tohoto sloupce:
SELECT id_user FROM uživatelů;

Pokud se potřebujete podívat například na jména a e-maily uživatelů, pak je potřeba uvést sloupce zájmu oddělené čárkami:
SELECT jméno, email FROM uživatelů;

Podobně můžete vidět, jaká data obsahují ostatní tabulky.
Nejprve se podívejme, jaká témata existují:
VYBRAT * Z témat;

Nyní jsou v tabulce pouze 4 témata, ale co když jich je 100? Přál bych si, aby byly zobrazeny například v abecedním pořadí. V SQL pro to existuje klíčové slovo SEŘADIT PODLE, za kterým následuje název sloupce, podle kterého proběhne řazení. Syntaxe je následující:
SELECT název_sloupce FROM název_tabulky ORDER BY název_sloupce_třídění;

Ve výchozím nastavení je řazení ve vzestupném pořadí, ale to lze změnit přidáním klíčového slova DESC.

Data jsou nyní řazena v sestupném pořadí.
Řazení lze provádět podle několika sloupců najednou. Například následující dotaz seřadí data podle sloupce topic_name, a pokud je v tomto sloupci více identických řádků, bude sloupec id_author seřazen v sestupném pořadí:

Porovnejte výsledek s výsledkem předchozího dotazu.
Uživatel velmi často nepotřebuje všechny informace z tabulky. Potřebujete například zjistit, která témata vytvořil uživatel sveta (id = 4). V SQL pro to existuje klíčové slovo KDE, syntaxe takového požadavku je následující:
SELECT název_sloupce FROM název_tabulky WHERE podmínka;
Pro náš příklad je podmínkou ID uživatele, tzn. Potřebujeme pouze ty řádky, jejichž sloupec id_author obsahuje 4 (ID uživatele sveta):
SELECT * FROM témat WHERE id_author=4;

Nyní musíme zjistit, kdo vytvořil téma „kola“:

Samozřejmě by bylo pohodlnější, kdyby se místo id autora zobrazovalo jeho jméno, ale jména jsou uložena v jiné tabulce. Dále se podíváme na to, jak vybrat data z více tabulek. Mezitím zjistíme, jaké podmínky lze nastavit pomocí klíčového slova WHERE.
| Operátor | Popis |
| = (rovná se) | Jsou vybrány hodnoty rovné zadané hodnotě. Příklad: SELECT * FROM témata WHERE id_author=4; Výsledek:  |
| > (více) | Jsou vybrány hodnoty vyšší než zadaná hodnota. Příklad: SELECT * FROM témata WHERE id_author > 2; Výsledek:  |
| < (меньше) | Jsou vybrány hodnoty menší než zadaná hodnota. Příklad: SELECT * FROM topics WHERE id_author< 3;
Результат:
 |
| >= (větší nebo rovno) | Jsou vybrány hodnoty větší a rovné zadané hodnotě. Příklad: SELECT * FROM témata WHERE id_author >= 2; Výsledek:  |
| <= (меньше или равно) | Jsou vybrány hodnoty menší a rovné zadané hodnotě. Příklad: SELECT * FROM topics WHERE id_author<= 3;
Результат:
 |
| != (není rovno) | Jsou vybrány hodnoty, které se nerovnají zadané hodnotě. Příklad: SELECT * FROM topics WHERE id_author != 1; Výsledek:  |
| NENÍ NULL | Vybere řádky, které mají hodnoty v zadaném poli. Příklad: SELECT * FROM témata WHERE id_author NENÍ NULL; Výsledek:  |
| JE NULL | Vybere řádky, které nemají hodnotu v zadaném poli. Příklad: SELECT * FROM témata WHERE id_author IS NULL; Výsledek:  Prázdná sada – žádné takové řádky nejsou. Prázdná sada – žádné takové řádky nejsou. |
| BETWEEN (mezi) | Hodnoty mezi zadanými jsou vybrány. Příklad: SELECT * FROM topics WHERE id_author BETWEEN 1 AND 3; Výsledek:  |
| IN (hodnota obsažená) | Vyberou se hodnoty odpovídající zadaným. Příklad: SELECT * FROM témata WHERE id_author IN (1, 4); Výsledek:  |
| NOT IN (hodnota není obsažena) | Jsou vybrány jiné hodnoty, než jsou zadané. Příklad: SELECT * FROM témata WHERE id_author NOT IN (1, 4); Výsledek:  |
| LIKE (shoda) | Vyberou se hodnoty, které odpovídají vzoru. Příklad: SELECT * FROM topics WHERE topic_name LIKE "led%"; Výsledek:  Možné metaznaky pro operátor LIKE budou diskutovány níže. Možné metaznaky pro operátor LIKE budou diskutovány níže. |
| NELÍBÍ SE (neodpovídá) | Jsou vybrány hodnoty, které neodpovídají vzoru. Příklad: SELECT * FROM topics WHERE topic_name NOT LIKE "led%"; Výsledek:  |
O různých jsem již psal SQL dotazy, ale je čas mluvit o složitějších věcech, např. SQL dotaz pro výběr záznamů z několika tabulek.
Když jsme vy a já vybírali z jedné tabulky, bylo vše velmi jednoduché:
SELECT názvy_požadovaných_polí FROM název_tabulky WHERE podmínka_výběru
Všechno je velmi jednoduché a triviální, ale odběr vzorků z několika stolů najednou Začíná to být trochu složitější. Jedním z problémů je shoda názvů polí. Například každá tabulka má pole id.
Podívejme se na tento dotaz:
SELECT * FROM tabulka_1, tabulka_2 WHERE tabulka_1.id > tabulka_2.id_uzivatele
Mnozí, kteří se s takovými dotazy nezabývali, si budou myslet, že je vše velmi jednoduché, protože si myslí, že před názvy polí byly přidány pouze názvy tabulek. Ve skutečnosti se tak vyhnete konfliktům mezi identickými názvy polí. Potíž však nespočívá v tom, ale v algoritmus pro takový SQL dotaz.
Pracovní algoritmus je následující: první záznam je převzat z stůl 1. bere id tento záznam od stůl 1. Níže je celá tabulka tabulka_2. A všechny záznamy jsou přidány tam, kde je hodnota pole uživatelské ID méně id vybraný záznam v stůl 1. Po první iteraci se tedy může objevit od 0 do nekonečného čísla výsledné záznamy. Při další iteraci se vezme další záznam tabulky stůl 1. Znovu se naskenuje celá tabulka tabulka_2 a znovu se spustí podmínka vzorkování table_1.id > table_2.user_id. Všechny záznamy splňující tuto podmínku jsou přidány do výsledku. Výstupem může být obrovské množství záznamů, mnohonásobně větší než celková velikost obou tabulek.
Pokud po prvním spuštění pochopíte, jak to funguje, je to skvělé, ale pokud ne, čtěte, dokud to plně nepochopíte. Pokud to pochopíte, bude to jednodušší.
Předchozí SQL dotaz, jako takový se používá zřídka. Bylo to prostě dáno za vysvětlení algoritmu pro výběr z několika tabulek. Nyní se podíváme na ten více zavalitý SQL dotaz. Řekněme, že máme dvě tabulky: se zbožím (je tam pole id_vlastníka zodpovědný za id vlastník produktu) a s uživateli (je zde pole id). Chceme jednu SQL dotaz získat všechny záznamy a každý z nich obsahuje informace o uživateli a jeho jednom produktu. Další záznam obsahoval informace o stejném uživateli a jeho dalším produktu. Když produkty tohoto uživatele dojdou, přejděte k dalšímu uživateli. Takže musíme spojit dva stoly a získat výsledek kde každý záznam obsahuje informace o uživateli a jednom z jeho produktů.
Podobný dotaz nahradí 2 SQL dotazy: vybrat samostatně z tabulky s produkty a z tabulky s uživateli. Navíc takový požadavek okamžitě spáruje uživatele a jeho produkt.
Samotný požadavek je velmi jednoduchý (pokud jste pochopili předchozí):
SELECT * FROM users, products WHERE users.id = products.owner_id
Algoritmus je zde již jednoduchý: vezme se první záznam z tabulky uživatelů. Dále se to vezme id a všechny záznamy z tabulky jsou analyzovány produkty, přidáním k výsledku ty s id_vlastníka rovná se id od stolu uživatelů. V první iteraci se tedy shromáždí veškeré zboží od prvního uživatele. Při druhé iteraci jsou shromážděny všechny produkty od druhého uživatele a tak dále.
Jak můžete vidět, SQL dotazy pro výběr z několika tabulek nejsou nejjednodušší, ale výhody z nich mohou být obrovské, takže znát a umět takové dotazy používat je velmi žádoucí.
Jste v programování nováčkem nebo jste se v minulosti jednoduše vyhýbali učení SQL? Pak jste na správné adrese, protože každý vývojář se nakonec potýká s potřebou znát tento dotazovací jazyk. Možná nejste hlavní návrhář databází, ale vyhnout se práci s nimi je téměř nemožné. Doufám, že tento stručný přehled základní syntaxe dotazů SQL pomůže vývojářům, kteří o to mají zájem, a komukoli dalšímu, kdo to potřebuje.
Co je to SQL databáze?
Structured Query Language je databázový komunikační standard, který podporuje ANSI. Poslední verzí je SQL-99, i když nový standard, SQL-200n, je již ve vývoji. Většina databází pevně dodržuje standard ANSI-92. Hodně se diskutovalo o zavedení modernějších standardů, ale komerční prodejci databází od toho odcházejí a vyvíjejí vlastní nové koncepty pro ukládání uložených dat. Téměř každá databáze používá nějakou jedinečnou sadu syntaxe, i když velmi podobnou standardu ANSI. Ve většině případů je tato syntaxe rozšířením základního standardu, i když existují případy, kdy tato syntaxe poskytuje různé výsledky pro různé databáze. Vždy je dobré zkontrolovat dokumentaci databáze, zvláště pokud získáváte neočekávané výsledky.
Pokud jste v SQL nováčkem, musíte pochopit některé základní pojmy.
Obecně řečeno, "SQL databáze" je obecný název pro systém správy relačních databází (RDBMS). Pro některé systémy "databáze" také odkazuje na skupinu tabulek, dat nebo konfiguračních informací, které jsou inherentně oddělenou částí od jiných podobných konstrukcí. V tomto případě může každá instalace SQL databáze sestávat z několika databází. V jiných systémech jsou označovány jako tabulky.
Tabulka je struktura databáze, která se skládá ze sloupců obsahujících řádky dat. Tabulky se obvykle vytvářejí tak, aby obsahovaly související informace. V rámci jedné databáze lze vytvořit více tabulek.
Každý sloupec představuje atribut nebo sadu atributů objektů, jako jsou identifikační čísla zaměstnanců, výška, barva vozu atd. Termín pole se často používá k označení sloupce, za nímž následuje název, například „v poli Název“. Řádkové pole je minimálním prvkem tabulky. Každý sloupec v tabulce má specifický název, datový typ a velikost. Názvy sloupců musí být v tabulce jedinečné.
Každý řádek (nebo záznam) představuje kolekci atributů konkrétního objektu, řádek může například obsahovat identifikační číslo zaměstnance, jeho plat, rok narození atd. Řádky tabulky nemají názvy. Pro přístup ke konkrétnímu řádku musí uživatel zadat nějaký atribut (nebo sadu atributů), který jej jednoznačně identifikuje.
Jednou z nejdůležitějších operací, které se při práci s daty provádějí, je získávání informací uložených v databázi. K tomu musí uživatel provést dotaz.
Nyní se podívejme na hlavní typy databázových dotazů, které se zaměřují na manipulaci s daty v databázi. Pro naše účely jsou všechny příklady poskytovány ve standardním SQL, aby vyhovovaly jakémukoli prostředí.
Typy datových dotazů
V SQL existují čtyři hlavní typy datových dotazů, které spadají pod takzvaný Data Manipulation Language (DML):
SELECT – výběr řádků z tabulek;
INSERT – přidání řádků do tabulky;
UPDATE – změna řádků v tabulce;
DELETE – smazání řádků v tabulce;
Každý z těchto dotazů má různé operátory a funkce, které se používají k provádění některých akcí s daty. Největší počet možností má dotaz SELECT. Ve spojení s SELECT se používají také další typy dotazů, jako je JOIN a UNION. My se ale zatím zaměříme pouze na základní dotazy.
Pomocí dotazu SELECT vyberte požadovaná data
K získání informací uložených v databázi se používá dotaz SELECT. Základní efekt tohoto dotazu je omezen na jednu tabulku, i když existují návrhy, které umožňují vybírat z více tabulek současně. Chcete-li získat všechny řádky dat pro konkrétní sloupce, použije se dotaz, jako je tento:
SELECT sloupec1, sloupec2 FROM název_tabulky;
Můžete také získat všechny sloupce z tabulky pomocí zástupného znaku "*":
SELECT * FROM název_tabulky;
To může být užitečné, když se chystáte vybrat data s konkrétní klauzulí WHERE. Následující dotaz vrátí všechny sloupce ze všech řádků, kde "sloupec1" obsahuje hodnotu "3":
SELECT * FROM název_tabulky WHERE sloupec1=3;
Kromě „=“ (rovná se) existují následující podmíněné operátory:
Podmíněná prohlášení:
= rovný
<>Ne rovné
> Více
<
Меньше
>= Větší než nebo rovno
<=
Меньше или равно
Kromě toho můžete použít podmínky BITWEEN a LIKE k porovnání s podmínkou WHERE a také kombinace operátorů AND a OR.
SELECT * FROM název_tabulky WHERE ((Věk >= 18) AND (Příjmení BETWEEN 'Ivanov' AND 'Sidorov')) OR Company LIKE '%Motorola%';
Co v ruském překladu znamená: vyberte všechny sloupce z tabulky název_tabulky, kde hodnota sloupce věk je větší nebo rovna 18 a hodnota sloupce Příjmení je v abecedním rozsahu od Ivanova po Sidorova včetně, nebo hodnota ve sloupci Společnost je Motorola.
Použití dotazu INSERT k vložení nových dat
Dotaz INSERT se používá k vytvoření nového řádku dat. Chcete-li aktualizovat existující data nebo prázdná řádková pole, musíte použít dotaz UPDATE.
Příklad syntaxe dotazu INSERT:
INSERT INTO název_tabulky (sloupec1, sloupec2, sloupec3) VALUES ('data1', 'data2', 'data3');
Pokud se chystáte vložit všechny hodnoty v pořadí, ve kterém se zobrazují sloupce tabulky, můžete názvy sloupců vynechat, i když je to vhodnější pro čitelnost. Také pokud uvádíte sloupce, nemusíte je uvádět v pořadí, v jakém se objevují v databázi, pokud zadané hodnoty odpovídají tomuto pořadí. Neměli byste vypisovat sloupce, které neobsahují informace.
Již existující informace v databázi se mění velmi podobným způsobem.
Dotaz AKTUALIZACE a podmínka WHERE
UPDATE se používá ke změně existujících hodnot nebo uvolnění pole v řádku, takže nové hodnoty musí odpovídat existujícímu datovému typu a poskytovat přijatelné hodnoty. Pokud nechcete měnit hodnoty ve všech řádcích, musíte použít klauzuli WHERE.
UPDATE název_tabulky SET sloupec1 = 'data1', sloupec2 = 'data2' WHERE sloupec3 = 'data3';
WHERE můžete použít na libovolný sloupec, včetně toho, který chcete změnit. To se používá, když je nutné nahradit jednu konkrétní hodnotu jinou.
UPDATE table_name SET FirstName = 'Vasily' WHERE FirstName = 'Vasily' AND LastName = 'Pupkin';
Buď opatrný! Dotaz DELETE odstraní celé řádky
Dotaz DELETE zcela odstraní řádek z databáze. Pokud chcete odstranit jedno pole, musíte použít požadavek UPDATE a nastavit toto pole na hodnotu, která bude ve vašem programu analogická s hodnotou NULL. Dejte pozor, abyste svůj dotaz DELETE omezili na klauzuli WHERE, jinak můžete ztratit celý obsah tabulky.
DELETE FROM název_tabulky WHERE sloupec1 = 'data1';
Jakmile je řádek smazán z databáze, nelze jej obnovit, proto je vhodné mít sloupec s názvem „IsActive“ nebo něco podobného, který můžete změnit na hodnotu null, což bude indikovat, že zobrazení dat z ten řádek je zamčený.
Nyní znáte základy SQL dotazů
SQL je databázový jazyk a my jsme pokryli nejdůležitější a základní příkazy používané v dotazech na data. Existuje mnoho základních pojmů, které nebyly pokryty (například SUM a COUNT), ale těch několik příkazů, které se nám podařilo uvést výše, by vás mělo povzbudit k tomu, abyste byli aktivní a ponořili se hlouběji do úžasného dotazovacího jazyka zvaného SQL.
Oddíl 4 Informační systémy
Úvod do SQL.
Vytváření, úpravy a mazání tabulek.
Načítání dat z tabulky.
Vytváření SQL dotazů.
Zpracování dat v SQL.
Metody výuky tohoto tématu ve škole.
Úvod do SQL. SQL je strukturovaný dotazovací jazyk, který umožňuje vytvářet a pracovat v relačních databázích, což jsou sady souvisejících informací uložených v tabulkách. Jazyk je zaměřen na operace s daty prezentovanými ve formě logicky propojených sad relačních tabulek. Nejdůležitější vlastností struktur tohoto jazyka je jeho zaměření na konečný výsledek zpracování dat, nikoli na postup při tomto zpracování. SQL sám určuje, kde jsou data umístěna, indexy a dokonce i to, jaká nejúčinnější sekvence operací by měla být použita k získání výsledku.
Zpočátku byl SQL hlavní způsob práce uživatele s databází a umožňoval provádět následující sadu operací: vytvoření nové tabulky v databázi; přidávání nových záznamů do tabulky; změna záznamů; mazání záznamů; výběr záznamů z jedné nebo více tabulek (v souladu s danou podmínkou); struktury měnícího se stolu.
V průběhu času SQL poskytoval možnost popisovat a spravovat nové uložené objekty (jako jsou indexy, pohledy, spouštěče a uložené procedury). SQL zůstává jediným komunikačním mechanismem mezi aplikačním softwarem a databází. Moderní DBMS, stejně jako informační systémy využívající DBMS, zároveň poskytují uživateli vyvinuté prostředky pro vizuální konstrukci dotazů. Každý SQL příkaz je buď žádost data z databáze, nebo volání do databáze, které vede ke změně dat v databázi.
Podle toho, jaké změny v databázi nastanou, se rozlišují následující typy požadavků: vytvořit nebo změnit nové nebo existující objekty v databázi; přijímat data; přidat nové údaje (záznamy); smazat data; přístup do DBMS.
Hlavním úložným objektem relační databáze je tabulka, takže všechny SQL dotazy jsou operacemi s tabulkami. V souladu s tím se požadavky dělí na:
Dotazy, které působí na samotné tabulky (vytváření a změna tabulek);
Dotazy, které pracují s jednotlivými záznamy (nebo řádky tabulky) nebo sadami záznamů.
Každá tabulka je popsána ve formě seznamu jejích polí (sloupců tabulky) s uvedením: typu hodnot uložených v každém poli; propojení mezi tabulkami (nastavení primárního a sekundárního klíče); informace potřebné k sestavení indexů.
Použití SQL tedy v podstatě spočívá v generování všech druhů výběrů řádků a provádění operací se všemi záznamy obsaženými v sadě.
SQL příkazy jsou rozděleny do následujících skupin:
1. Příkazy jazyka pro definici dat - DDL (Data Definition Language). Tyto příkazy SQL lze použít k vytvoření, úpravě a odstranění různých databázových objektů.
2. Příkazy jazyka kontroly dat - DCL (Data Control Language). Pomocí těchto SQL příkazů můžete řídit přístup uživatelů k databázi a používat konkrétní data (tabulky, pohledy atd.).
3. Příkazy jazyka řízení transakcí - TCL (Tganstation Control Language). Tyto příkazy SQL vám umožňují určit výsledek transakce.
4. Příkazy jazyka pro manipulaci s daty - DML (Data Manipulation Language). Tyto příkazy SQL umožňují uživateli přesouvat data do a z databáze.
SQL příkazy se dělí na:
Operátory definice dat ( Data Definition Language, DDL)
CREATE vytvoří databázový objekt (samotnou databázi, tabulku, pohled, uživatele atd.)
ALTER změní objekt
DROP odstraní objekt
Operátoři manipulace s daty ( Jazyk pro manipulaci s daty, DML)
SELECT čte data, která splňují zadané podmínky
INSERT přidá nová data
UPDATE upravuje existující data
DELETE smaže data
Operátoři definice přístupu k datům ( Data Control Language, DCL)
GRANT uděluje uživateli (skupině) oprávnění k určitým operacím s objektem
REVOKE ruší dříve vydaná oprávnění
DENY určuje zákaz, který má přednost před povolením
Kontrolní výpisy transakcí ( Jazyk řízení transakcí, TCL)
COMMIT použije transakci.
ROLLBACK vrátí zpět všechny změny provedené v kontextu aktuální transakce.
SAVEPOINT rozděluje transakci na menší části.
výhody: 1. Nezávislost na konkrétním DBMS (texty SQL dotazů obsahující DDL a DML lze celkem snadno přenášet z jednoho DBMS do druhého). 2. Dostupnost standardů (přítomnost standardů a sady testů pro zjištění kompatibility a souladu konkrétní implementace SQL s obecně uznávaným standardem pouze přispívá ke „stabilizaci“ jazyka). 3. Deklarativní (pomocí SQL programátor popisuje pouze to, jaká data je třeba extrahovat nebo upravit)
nedostatky: 1. Nekonzistence s relačním datovým modelem 2. Opakované řádky 3. Nuly 4. Explicitní určení pořadí sloupců zleva doprava 5. Nepojmenované sloupce a duplicitní názvy sloupců 6. Nedostatečná podpora pro vlastnost „=“ 7. Použití ukazatele 8. Vysoká redundance
2.2 Vytváření, změna a mazání tabulek.
Vytvoření tabulky:
Tabulky se vytvářejí pomocí příkazu CREATE TABLE. Tento příkaz vytvoří prázdnou tabulku - tabulku bez řádků. Hodnoty se zadávají pomocí příkazu DML INSERT. Příkaz CREATE TABLE v podstatě definuje tabulky popisem sady názvů sloupců zadaných v určitém pořadí. Definuje také datové typy a velikosti sloupců. Každá tabulka musí mít alespoň jeden sloupec.
Syntaxe příkazu:
VYTVOŘIT TABULKU
(
Změna stolu:
Příkaz ALTER TABLE je smysluplná forma, i když jeho možnosti jsou poněkud omezené. Používá se ke změně definice existující tabulky. Obvykle přidává sloupce do tabulky. Někdy může odstranit nebo změnit velikost sloupců a v některých programech přidat nebo odebrat omezení. Typická syntaxe pro přidání sloupce do tabulky je:
ALTER TABULKA
|
titul |
ročník hospody |
vydavatel |
K tomu musí DBMS nejprve sloučit tabulky titulů a vydavatelů , a teprve poté z výsledného vztahu udělejte vzorek.
Chcete-li provést tento druh operace v příkazu VYBRAT za klíčovým slovem Z označuje seznam tabulek, přes které se prohledávají data. Po klíčovém slově KDE je uvedena podmínka, za které se fúze provádí. Chcete-li provést tento požadavek, musíte zadat příkaz:
VYBERTE tituly. titul, tituly. ročník hospody, nakladatelství. vydavatel
OD titulů, vydavatelů
WHERE titles.pub_id=publishers.pub_id;
Příklad, kde jsou současně zadány podmínky sloučení i výběru (výsledek předchozího dotazu je omezen na publikace po roce 1996):
VYBERTE tituly.titul,tituly.ročníkpub,vydavatelé.vydavatel
OD titulů, vydavatelů
WHERE titles.pub_id=publishers.pub_id AND
titles.yearpub>1996;
Vezměte prosím na vědomí, že pokud jsou v různých tabulkách pole stejného názvu, je před názvem pole uveden název tabulky a znak „.“ (tečka). (Doporučujeme vždy uvádět název tabulky!)
Přirozeně je možné sloučit více než dvě tabulky. Chcete-li například výše popsaný výběr doplnit o jména autorů knih, musíte vytvořit operátor v následujícím tvaru:
Publishers.publisher
OD titulů, vydavatelů, autorů titulů, autorů
WHERE titleauthors.au_id=authors.au_id AND
Titleauthors.title_id=titles.title_id AND
Titles.pub_id=publishers.pub_id AND
Tituly. ročník hospody > 1996;
Alternativou ke sloučení více tabulek může být použití operátoru
spojování tabulek přímo v klauzuli Z. Tam jsou tři
možnost operátora:
VNITŘNÍ SPOJENÍ spojení, ve kterém jsou záznamy zahrnuty do výsledku
nastavit pouze v případě, že jsou v souvisejících atributech nalezeny stejné atributy
hodnoty;
PŘIPOJIT SE VLEVO levé spojení, ve kterém jsou všechny záznamy z prvního (zleva)
tabulky jsou zahrnuty do sady výsledků, i když v druhé (vpravo)
v tabulce nejsou žádné odpovídající záznamy;
SPRÁVNÉ PŘIPOJENÍ SE pravé spojení, ve kterém jsou všechny záznamy z druhého (vpravo)
tabulky jsou zahrnuty do sady výsledků, i když první (levá) tabulka
neexistují žádné odpovídající záznamy.
Například předchozí příklad by mohl být implementován pomocí operátoru
INNER JOIN takto:
SELECT autoři.autor,názvy.název,názvy.ročník,
Publishers.publisher
FROM ((názvy INNER JOIN publishers ON
Titles.pub_id=publishers.pub_id)
INNER JOIN autoři titulů ON
Itleauthors.title_id=titles.title_id)
VNITŘNÍ PŘIPOJENÍ autorů ON
Titleauthors.au_id=authors.au_id
WHERE tituly.ročníkpub > 1996;
3. Výpočty uvnitř SELECT.
SQL umožňuje provádět různé aritmetické operace na sloupcích výsledného vztahu. V designu<список_выбора> Můžete použít konstanty, funkce a jejich kombinace s aritmetickými operacemi a závorkami. Chcete-li například zjistit, kolik let uplynulo od roku 1992 (rok přijetí standardu SQL-92) do vydání konkrétní knihy, můžete spustit příkaz:
SELECT titul, ročník-1992 FROM titulů WHERE ročník > 1992;
Aritmetické výrazy umožňují operace sčítání (+), odčítání (-),
dělení (/), násobení (*) a také různé funkce (COS, SIN, ABS
absolutní hodnota atd.).
V SQL jsou také definovány tzv. agregační funkce, které provádějí akce na množině identických polí ve skupině záznamů. Mezi nimi:
AVG(<имя поля>) - průměr ze všech hodnot tohoto pole
POČET(<имя поля>) nebo COUNT (*) - počet záznamů
MAX(<имя поля>) - maximum ze všech hodnot tohoto pole
MIN(<имя поля>) - minimum všech hodnot tohoto pole
SOUČET(<имя поля>) - součet všech hodnot tohoto pole
Upozorňujeme, že každá agregační funkce vrací jednu hodnotu.
Příklady: určete datum vydání nejstarší knihy v naší databázi
SELECT MIN(yearpub) FROM titulů;
SELECT COUNT (*) FROM titulů ;
Rozsah funkčních dat lze omezit pomocí logické podmínky. Například počet knih vydaných po roce 2000:
SELECT COUNT (*) FROM titulů WHERE ročníkpub > 2000;
4. Funkce pro práci s daty
V MS Access Existuje celá sada vestavěných funkcí data a času. Uveďme některé z nich:
Datum() - aktuální datum, tj. dnešní datum, měsíc a rok;
D den (datum) - extrahuje den z data, například datum- 12.09.97, číslo 12;
Měsíc (datum) - extrahuje měsíc z data, například data - 12,09,97, výsledek aplikace funkce- číslo 9;
Ueag(datum) - extrahuje rok z data, například data - 12-09,97, výsledek aplikace funkce- číslo 97;
Den v týdnu (datum) - extrahuje den v týdnu v americkém systému číslování dnů z data, konkrétně v příkladu- datum 12.09.97, výsledkem aplikace funkce je číslo 6, což odpovídá pátku
DatePart(HHTepBan, datum) - zde je argument "interval" - je zkrácený název pro požadovanou komponentu data a datum - konkrétní hodnotu data nebo název pole data
Například:
DatePart ("H",#12,09,97#) - den v týdnu - 6, tj. pátek,
DatePart ("HH",#12,09,97#) - týden v roce - 37,
DatePart (" K ",# 12,09,97#) - čtvrtletí roku - 3
DatePart("a",#12,09,97#) - den -12,
DatePart("M",#12,09,97#) - měsíc - 9, \ DatePart("rrrr",#12,09,97#) - rok -1997
Příklad žádosti. Určete, kolik let uplynulo od zveřejnění článku popisujícího normu SQL (předpokládejme, že název článku je „Standardní SQL")
VYBERTE měsíc(datum()-rokpub)
Z titulů INNER JOIN vydavatelů ON
titles.pub_id = publishers.pub_id
WHERE vydavatel = "SQL Standard";
5. Laboratorní úloha
Poznámky k postupu laboratorních prací.
Pro zobrazení výsledků provádění dotazů je nutné, aby do tabulek byly zadány údaje odpovídající formulovaným dotazům. V tomto případě lze údaje v požadavcích (data, jména, množství atd.) po vložení údajů do databáze změnit.
Při provádění laboratorních úloh nahraďte všechna vypočítaná pole synonymy pomocí možnosti AS v klauzuli SELECT.
Například: SELECT COUNT (*) AS Počet řádků FROM nadpisů;
Implementujte následující dotazy pomocí SQL:
Najděte objednávky uskutečněné v lednu.
Najděte produkty, které jsou dodávány v množství ne menším než 10 a ne více než 100.
Získejte seznam produktů, které zákazník obdržel ze závodu „Krásný Luch“, jejichž cena je vyšší než 50 tisíc UAH.
Kolik dílů „Bolt“ obdržel zákazník „Krásný Luch“ ze všech objednávek?
Určete názvy dílů objednaných v období od 6/10/97 až 10.10.97, kterou jsem si neobjednalrostlina "Red Ray".
Získejte seznam názvů produktů, jejichž dodávky přesahují 10 tis.
Jaké množství dílů objednává závod Krasnyj Luch?
Kteří zákazníci si objednali díl Bolt?
Určete průměrný počet dodávek části Bolt za rok 1997.
Najděte zákazníka, který si objednal nejdražší díl.
6. Bezpečnostní otázky
Jaké jsou nabídky? VYBRAT jsou povinne?
Na co se věta ptá? KDE?
Jaké typy připojení ( PŘIPOJIT ) podporované pokyny VYBRAT?
Jaká je posloupnost vět instrukce VYBRAT?
Kdy je nutné uvést název tabulky před název pole?
Jak vytvořit vypočítaná pole v VYBRAT?
Je možné spojit více než dva stoly pomocí operace? PŘIPOJIT SE?
Jaká je alternativní syntaxe operace PŘIPOJIT (použitím KDE ) lze použít ke správnému provedení požadavku?