Готовые sql запросы. Простые запросы на выборку данных средствами SQL. Выборка всех столбцов
Итак, в БД forum есть три таблицы:
· users (пользователи);
· topics (темы);
· posts (сообщения).
Необходимо посмотреть, какие данные в них содержатся. Для этого в SQL существует оператор SELECT . Синтаксис его использования следующий:
SELECT что_выбрать FROM откуда_выбрать;
Вместо «что_выбрать» необходимо указать либо имя столбца, значения которого хотим увидеть, либо имена нескольких столбцов через запятую, либо символ звездочки (*), означающий выбор всех столбцов таблицы. Вместо «откуда_выбрать» следует указать имя таблицы.
Сначала посмотрим все столбцы из таблицы users:
SELECT * FROM users;
Это все данные, которые были внесены в таблицу.
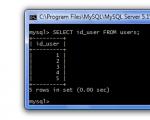
Предположим, что необходимо посмотреть только столбец id_user (так как для заполнения таблицы topics (темы) надо знать, какие id_user есть в таблице users). Для этого в запросе укажем имя этого столбца:
SELECT id_user FROM users;

Если необходимо посмотреть, например, имена и e-mail пользователей, то надо перечислить интересующие столбцы через запятую:
SELECT name, email FROM users;

Аналогично, можно посмотреть, какие данные содержат и другие таблицы.
Сначала посмотрим, какие существуют темы:
SELECT * FROM topics;

Сейчас в таблице всего 4 темы, а если их будет 100? Хотелось бы, чтобы они выводились, например, по алфавиту. Для этого в SQL существует ключевое слово ORDER BY , после которого указывается имя столбца, по которому будет происходить сортировка. Синтаксис следующий:
SELECT имя_столбца FROM имя_таблицы ORDER BY имя_столбца_сортировки;

По умолчанию сортировка идет по возрастанию, но это можно изменить, добавив ключевое слово DESC .

Теперь данные отсортированы в порядке по убыванию.
Сортировку можно производить сразу по нескольким столбцам. Например, следующий запрос отсортирует данные по столбцу topic_name, и если в этом столбце будет несколько одинаковых строк, то в столбце id_author будет осуществлена сортировка по убыванию:

Сравните результат с результатом предыдущего запроса.
Очень часто пользователю не нужна вся информация из таблицы. Например, необходимо узнать, какие темы были созданы пользователем sveta (id = 4). Для этого в SQL есть ключевое слово WHERE , синтаксис у такого запроса следующий:
SELECT имя_столбца FROM имя_таблицы WHERE условие;
Для нашего примера условием является идентификатор пользователя, т.е. нужны только те строки, в столбце id_author которых стоит 4 (идентификатор пользователя sveta):
SELECT * FROM topics WHERE id_author=4;

Теперь необходимо узнать, кто создал тему «велосипеды»:

Конечно, было бы удобнее, чтобы вместо id автора, выводилось его имя, но имена хранятся в другой таблице. Далее рассмотрим, как выбирать данные из нескольких таблиц. А пока узнаем, какие условия можно задавать, используя ключевое слово WHERE.
| Оператор | Описание |
| = (равно) | Отбираются значения равные указанному.
Пример: SELECT * FROM topics WHERE id_author=4;
Результат:
 |
| > (больше) | Отбираются значения больше указанного.
Пример: SELECT * FROM topics WHERE id_author > 2;
Результат:
 |
| < (меньше) | Отбираются значения меньше указанного.
Пример: SELECT * FROM topics WHERE id_author < 3;
Результат:
 |
| >= (больше или равно) | Отбираются значения большие и равные указанному.
Пример: SELECT * FROM topics WHERE id_author >= 2;
Результат:
 |
| <= (меньше или равно) | Отбираются значения меньшие и равные указанному.
Пример: SELECT * FROM topics WHERE id_author <= 3;
Результат:
 |
| != (не равно) | Отбираются значения не равные указанному.
Пример: SELECT * FROM topics WHERE id_author != 1;
Результат:
 |
| IS NOT NULL | Отбираются строки, имеющие значения в указанном поле.
Пример: SELECT * FROM topics WHERE id_author IS NOT NULL;
Результат:
 |
| IS NULL | Отбираются строки, не имеющие значения в указанном поле.
Пример: SELECT * FROM topics WHERE id_author IS NULL;
Результат:
 Empty set – нет таких строк.
Empty set – нет таких строк.
|
| BETWEEN (между) | Отбираются значения, находящиеся между указанными.
Пример: SELECT * FROM topics WHERE id_author BETWEEN 1 AND 3;
Результат:
 |
| IN (значение содержится) | Отбираются значения, соответствующие указанным.
Пример: SELECT * FROM topics WHERE id_author IN (1, 4);
Результат:
 |
| NOT IN (значение не содержится) | Отбираются значения, кроме указанных.
Пример: SELECT * FROM topics WHERE id_author NOT IN (1, 4);
Результат:
 |
| LIKE (соответствие) | Отбираются значения, соответствующие образцу.
Пример: SELECT * FROM topics WHERE topic_name LIKE "вел%";
Результат:
 Возможные метасимволы оператора LIKE будут рассмотрены ниже.
Возможные метасимволы оператора LIKE будут рассмотрены ниже.
|
| NOT LIKE (не соответствие) | Отбираются значения, не соответствующие образцу.
Пример: SELECT * FROM topics WHERE topic_name NOT LIKE "вел%";
Результат:
 |
Я уже писал о самых различных SQL-запросах , но пришло время поговорить и о более сложных вещах, например, SQL-запрос на выборку записей из нескольких таблиц .
Когда мы с Вами делали выборку из одной таблицы, то всё было очень просто:
SELECT названия_нужных_полей FROM название_таблицы WHERE условие_выборки
Всё очень просто и тривиально, но при выборке сразу из нескольких таблиц становится всё несколько сложнее. Одна из трудностей - это совпадение имён полей. Например, в каждой таблице есть поле id .
Давайте рассмотрим такой запрос:
SELECT * FROM table_1, table_2 WHERE table_1.id > table_2.user_id
Многим, кто не занимался подобными запросами, покажется, что всё очень просто, подумав, что здесь добавились только названия таблиц перед названиями полей. Фактически, это позволяет избежать противоречий между одинаковыми именами полей. Однако, сложность не в этом, а в алгоритме работы подобного SQL-запроса .
Алгоритм работы следующий: берётся первая запись из table_1 . Берётся id этой записи из table_1 . Дальше полностью смотрится таблица table_2 . И добавляются все записи, где значение поля user_id меньше id выбранной записи в table_1 . Таким образом, после первой итерации может появиться от 0 до бесконечного количества результирующих записей. На следующей итерации берётся следующая запись таблицы table_1 . Снова просматривается вся таблица table_2 , и вновь срабатывает условие выборки table_1.id > table_2.user_id . Все записи, удовлетворившие этому условию, добавляются в результат. На выходе может получиться огромное количество записей, во много раз превышающих суммарный размер обеих таблиц.
Если Вы поняли, как это работает после первого раза, то очень здорово, а если нет, то читайте до тех пор, пока не вникните окончательно. Если Вы это поймёте, то дальше будет проще.
Предыдущий SQL-запрос , как таковой, редко используется. Он был просто дан для объяснения алгоритма выборки из нескольких таблиц . А теперь же разберём более приземистый SQL-запрос . Допустим, у нас есть две таблицы: с товарами (есть поле owner_id , отвечающего за id владельца товара) и с пользователями (есть поле id ). Мы хотим одним SQL-запросом получить все записи, причём чтобы в каждой была информация о пользователе и его одном товаре. В следующей записи была информация о том же пользователе и следущем его товаре. Когда товары этого пользователя кончатся, то переходить к следующему пользователю. Таким образом, мы должны соединить две таблицы и получить результат, в котором каждая запись содержит информацию о пользователе и об одном его товаре .
Подобный запрос заменит 2 SQL-запроса : на выборку отдельно из таблицы с товарами и из таблицы с пользователями. Вдобавок, такой запрос сразу поставит в соответствие пользователя и его товар.
Сам же запрос очень простой (если Вы поняли предыдущий):
SELECT * FROM users, products WHERE users.id = products.owner_id
Алгоритм здесь уже несложный: берётся первая запись из таблицы users . Далее берётся её id и анализируются все записи из таблицы products , добавляя в результат те, у которых owner_id равен id из таблицы users . Таким образом, на первой итерации собираются все товары у первого пользователя. На второй итерации собираются все товары у второго пользователя и так далее.
Как видите, SQL-запросы на выборку из нескольких таблиц не самые простые, но польза от них бывает колоссальная, поэтому знать и уметь использовать подобные запросы очень желательно.
Вы новичок в программировании или же просто раньше избегали изучения SQL? Тогда вы попали по нужному адресу, так как любой разработчик в конце-концов сталкивается с необходимостью знать этот язык запросов. Пусть вы и не будете главным дизайнером баз данных, но работы с ними избежать практически невозможно. Я надеюсь этот краткий обзор синтаксиса основных SQL-запросов поможет заинтересованному разработчику и любому, кому это понадобится.
Что такое база данных SQL?
Структурированный язык запросов (Structured Query Language) – стандарт коммуникации с базой данных, который поддержан ANSI. Самая последняя версия – SQL-99, хотя новый стандарт SQL-200n уже находится в разработке. Большинство баз данных твердо придерживается стандарта ANSI-92. Было много обсуждений по поводу введения более современных стандартов, но изготовители коммерческих баз данных отклоняются от этого, развивая свои новые концепции манипуляции хранимыми данными. Почти каждая отдельная база данных использует некоторый уникальный набор синтаксиса, хоть и очень сильно подобного стандарту ANSI. В большинстве случаев, этот синтаксис является расширением базового стандарта, хотя бывают случаи, когда такой синтаксис приводит к различным результатам для разных баз данных. Всегда неплохой идеей будет просмотр документации к базе данных, особенно, если получаются неожиданные результаты.
Если вы впервые встречаетесь с SQL, то необходимо ознакомиться с основными концепциями, которые нужно понять.
В общих терминах, «SQL база данных» является общим названием для реляционной системы управления базами данных (РСУБД). Для некоторых систем, «база данных» также относится к группе таблиц, данных, конфигурационной информации, которые являются неотъемлемо отдельной частью от других, подобных конструкций. В этом случае, каждая инсталляция SQL базы данных может состоять из нескольких баз данных. В других системах, они упомянуты как таблицы.
Таблица – конструкция базы данных, которая состоит из столбцов, содержащих строки данных. Обычно таблицы созданы для того, чтобы содержать связанную информацию. В пределах той же самой базы данных могут быть созданы несколько таблиц.
Каждый столбец представляет собой атрибут или совокупность атрибутов объектов, например идентификационные номера служащих, рост, цвет машин и т.п. Часто в отношении столбца используется термин поле с указанием имени, например «в поле Name». Поле строки является минимальным элементом таблицы. Каждый столбец в таблице имеет определенное имя, тип данных и размер. Имена столбцов должны быть уникальны в пределах таблицы.
Каждая строка (или запись) представляет собой совокупность атрибутов конкретного объекта, например, в строке может содержаться идентификационный номер служащего, размер его зарплаты, год его рождения и т.д. Строки таблиц не имеют названий. Чтобы обратиться к конкретной строке, пользователю необходимо указать какой-то атрибут (или набор атрибутов), уникально ее идентифицирующий.
Одной из важнейших операций, которые выполняются при работе с данными, является выборка хранящейся в базе данных информации. Для этого пользователь должен выполнить запрос (query).
Теперь давайте рассмотрим основные типы запросов к базе данных, которые сосредоточены на манипуляции данными в пределах базы. Для наших целей, все примеры приведены в стандартном SQL, дабы соответствовать любой среде.
Типы запросов данных
Есть четыре основных типа запросов данных в SQL, которые относятся к так называемому языку манипулирования данными (Data Manipulation Language или DML):
SELECT
– выбрать строки из таблиц;
INSERT
– добавить строки в таблицу;
UPDATE
– изменить строки в таблице;
DELETE
– удалить строки в таблице;
Каждый из этих запросов имеет различные операторы и функции, которые используются для того, чтобы произвести какие-то действия с данными. Запрос SELECT имеет самое большое количество опций. Существуют также дополнительные типы запросов, используемых вместе с SELECT, типа JOIN и UNION. Но пока, мы сосредоточимся только на основных запросах.
Использование запроса SELECT для выборки нужных данных
Чтобы получить информацию, хранящуюся в базе данных используется запрос SELECT. Базовое действие этого запроса ограничено одной таблицей, хотя существуют конструкции, обеспечивающие выборку с нескольких таблиц одновременно. Для того, чтобы получить все строки данных для специфических столбцов, используется запрос такого вида:
SELECT column1, column2 FROM table_name;
Также, можно получить все столбцы из таблицы, используя подстановочный знак «*»:
SELECT * FROM table_name;
Это может быть полезно в том случае, когда вы собираетесь выбрать данные с определенным условием WHERE. Следующий запрос возвратит все столбцы со всех строк, где «column1» содержит значение «3»:
SELECT * FROM table_name WHERE column1=3;
Кроме «=» (равно), существуют следующие условные операторы:
Условные операторы:
= Равно
<>
Не равно
>
Больше
<
Меньше
>=
Больше или равно
<=
Меньше или равно
Дополнительно можно использовать условия BITWEEN и LIKE для сравнения с условием WHERE, а так же комбинации операторов AND и OR.
SELECT * FROM table_name WHERE ((Age >= 18) AND (LastName BETWEEN ‘Иванов’ AND ‘Сидоров’)) OR Company LIKE ‘%Motorola%’;
Что в переводе на русский язык означает: выбрать все столбцы из таблицы table_name, где значение столбца age больше или равно 18, а также значение столбца LastName находится в алфавитном промежутке от Иванов до Сидоров включительно, или же значением столбца Company является Motorola.
Использование запроса INSERT для вставки новых данных
Запрос INSERT используется для создания новой строки данных. Для обновления уже существующих данных или пустых полей строки нужно использовать запрос UPDATE.
Примерный синтаксис запроса INSERT:
INSERT INTO table_name (column1, column2, column3) VALUES (‘data1’, ‘data2’, ‘data3’);
Если вы собираетесь вставлять все значения в порядке, в котором находятся столбцы таблицы, то можно и не указывать имена столбцов, хотя для удобочитаемости это предпочтительнее. Кроме того, если вы перечисляете столбцы, необязательно указывать их по порядку нахождения в базе данных, пока значения, которые вы вводите, соответсвуют этому порядку. Вы не должны перечислять столбцы, в которые не вводится информация.
Изменяется уже существующая информация в базе данных очень похожим образом.
Запрос UPDATE и условие WHERE
UPDATE используется для того, чтобы изменить существующие значения или освободить поле в строке, поэтому новые значения должны соответствовать существующему типу данных и обеспечивать приемлемые значения. Если вы не хотите изменить значения во всех строках, то нужно использовать условие WHERE.
UPDATE table_name SET column1 = ‘data1’, column2 = ‘data2’ WHERE column3 = ‘data3’;
Вы можете использовать WHERE для любого столбца, включая тот, который хотите изменить. Это используется когда необходимо заменить одно определенное значение на другое.
UPDATE table_name SET FirstName = ‘Василий’ WHERE FirstName = ‘Василий’ AND LastName = ‘Пупкин’;
Будьте осторожны! Запрос DELETE удаляет целые строки
Запрос DELETE полность удаляет строку из базы данных. Если вы хотите удалить одно единственное поле, то нужно использовать запрос UPDATE и установить для этого поля значение, которое будет являться аналогом NULL в вашей программе. Будьте внимательны, и ограничивайте ваш запрос DELETE условием WHERE, иначе вы можете потерять все содержимое таблицы.
DELETE FROM table_name WHERE column1 = ‘data1’;
Как только строка была удалена из вашей базы данных, она не подлежит восстановлению, поэтому желательно иметь столбец по имени «IsActive», или что-то типа того, который вы можете изменить на ноль, что будет указывать на блокировку представления данных из этой строки.
Теперь вы знаете основы SQL запросов
SQL – язык баз данных, и мы рассмотрели наиболее важные и базовые команды, используемые в запросах данных. Множество основных концепций не были затронуты (SUM и COUNT например), но те немногие команды, которые удалось перечислить выше, должны побудить вас к активным действиям и более глубокому изучению замечательного языка запросов под именем SQL.
Раздел 4 Информационные системы
Введение в SQL.
Создание, изменение и удаление таблиц.
Выборка данных из таблицы.
Создание SQL-запросов.
Обработка данных в SQL.
Методика обучения данной теме в школе.
Введение в SQL. SQL - структурированный язык запросов, который дает возможность создавать и работать в реляционных базах данных, которые являются наборами связанной информации сохраняемой в таблицах. Язык ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц-отношений. Важнейшая особенность структур этого языка состоит в ориентации на конечный рез-тат обработки данных, а не на процедуру этой обработки. SQL сам определяет, где находятся данные, индексы и даже какие наиболее эффективные последовательности операций следует использовать для получения рез-та.
Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций: создание в базе данных новой таблицы; добавление в таблицу новых записей; изменение записей; удаление записей; выборка записей из одной или нескольких таблиц (в соответствии с заданным условием); изменение структур таблиц.
Со временем SQL обеспечил возможность описания и управления новыми хранимыми объектами (например, индексы, представления, триггеры и хранимые процедуры). SQL остаётся единственным механизмом связи между прикладным программным обеспечением и базой данных. В то же время, современные СУБД, а, также, информационные системы, использующие СУБД, предоставляют пользователю развитые средства визуального построения запросов. Каждое предложение SQL - это либо запрос данных из базы, либо обращение к базе данных, которое приводит к изменению данных в базе.
В соответствии с тем, какие изменения происходят в базе данных, различают следующие типы запросов: на создание или изменение в базе данных новых или существующих объектов; на получение данных; на добавление новых данных (записей); на удаление данных; обращения к СУБД.
Основным объектом хранения реляционной базы данных является таблица, поэтому все SQL-запросы - это операции над таблицами. В соответствии с этим, запросы делятся на:
Запросы, оперирующие самими таблицами (создание и изменение таблиц);
Запросы, оперирующие с отдельными записями (или строками таблиц) или наборами записей.
Каждая таблица описывается в виде перечисления своих полей (столбцов таблицы) с указанием: типа хранимых в каждом поле значений; связей между таблицами (задание первичных и вторичных ключей); информации, необходимой для построения индексов.
Таким образом, использование SQL сводится, по сути, к формированию всевозможных выборок строк и совершению операций над всеми записями, входящими в набор.
Команды SQL разделяются на следующие группы:
1. Команды языка определения данных - DDL (Data Definition Language). Эти SQL команды можно использовать для создания, изменения и удаления различных объектов базы данных.
2. Команды языка управления данными - DCL (Data Control Language). С помощью этих SQL команд можно управлять доступом пользователей к базе данных и использовать конкретные данные (таблицы, представления и т.д.).
3. Команды языка управления транзакциями - TCL (Тгаnsасtiоn Соntrol Language). Эти SQL команды позволяют определить исход транзакции.
4. Команды языка манипулирования данными - DML (Data Manipulation Language). Эти SQL команды позволяют пользователю перемещать данные в базу данных и из нее.
Операторы SQL делятся на:
Операторы определения данных (Data Definition Language, DDL )
CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.)
ALTER изменяет объект
DROP удаляет объект
Операторы манипуляции данными (Data Manipulation Language, DML )
SELECT считывает данные, удовлетворяющие заданным условиям
INSERT добавляет новые данные
UPDATE изменяет существующие данные
DELETE удаляет данные
Операторы определения доступа к данным (Data Control Language, DCL )
GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
REVOKE отзывает ранее выданные разрешения
DENY задает запрет, имеющий приоритет над разрешением
Операторы управления транзакциями (Transaction Control Language, TCL )
COMMIT применяет транзакцию.
ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции.
SAVEPOINT делит транзакцию на более мелкие участки.
Преимущества: 1.Независимость от конкретной СУБД (тексты SQL-запросов, содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую). 2. Наличие стандартов (наличие стандартов и набора тестов для выявления совместимости и соответствия конкретной реализации SQL общепринятому стандарту только способствует «стабилизации» языка). 3. Декларативность (с помощью SQL программист описывает только то, какие данные нужно извлечь или модифицировать)
Недостатки: 1.Несоответствие реляционной модели данных 2.Повторяющиеся строки 3. Неопределённые значения (nulls) 4. Явное указание порядка колонок слева направо 5. Колонки без имени и дублирующиеся имена колонок 6. Отсутствие поддержки свойства «=» 7. Использование указателей 8. Высокая избыточность
2.2 Создание, изменение и удаление таблиц.
Создание таблицы:
Таблицы создаются командой CREATE TABLE. Эта команда создает пустую таблицу - таблицу без строк. Значения вводятся с помощью DML команды INSERT. Команда CREATE TABLE в основном определяет им таблицы, в виде описания набора имен столбцов указанных в определенном порядке. Она также определяет типы данных и размеры столбцов. Каждая таблица должна иметь по крайней мере один столбец.
Синтаксис команды:
CREATE TABLE
(
Изменение таблицы:
Команда ALTER TABLE – это содержательна форма, хотя ее возможности несколько ограничены. Она используется чтобы изменить определение существующей таблицы. Обычно, она добавляет столбцы к таблице. Иногда она может удалять столбцы или изменять их размеры, а также в некоторых программах добавлять или удалять ограничения. Типичный синтаксис чтобы добавить столбец к таблице:
ALTER TABLE
|
title |
yearpub |
publisher |
Для этого СУБД предварительно должна выполнить слияние таблиц titles и publishers , и только затем произвести выборку из полученного отношения.
Для выполнения операции такого рода в операторе SELECT после ключевого слова FROM указывается список таблиц, по которым производится поиск данных. После ключевого слова WHERE указывается условие, по которому производится слияние. Для того, чтобы выполнить данный запрос, нужно дать команду:
SELECT titles . title , titles . yearpub , publishers . publisher
FROM titles,publishers
WHERE titles.pub_id=publishers.pub_id;
Пример, где одновременно задаются условия и слияния, и выборки (результат предыдущего запроса ограничивается изданиями после 1996 года):
SELECT titles.title,titles.yearpub,publishers.publisher
FROM titles,publishers
WHERE titles.pub_id=publishers.pub_id AND
titles.yearpub>1996;
Следует обратить внимание на то, что когда в разных таблицах присутствуют одноименные поля, то для устранения неоднозначности перед именем поля указывается имя таблицы и знак "." (точка). (Рекомендуется имя таблицы указывать всегда! )
Естественно, имеется возможность производить слияние и более чем двух таблиц. Например, чтобы дополнить описанную выше выборку именами авторов книг необходимо составить оператор следующего вида:
Publishers.publisher
FROM titles,publishers,titleauthors,authors
WHERE titleauthors.au_id=authors.au_id AND
Titleauthors.title_id=titles.title_id AND
Titles.pub_id=publishers.pub_id AND
Titles . yearpub > 1996;
Альтернативный вариант слияния нескольких таблиц может использовать оператор
соединения таблиц непосредственно в предложении FROM . Существует три
варианта оператора:
INNER JOIN соединение, при котором записи включаются в результирующий
набор только в том случае, если в связных атрибутах будут найдены одинаковые
значения;
LEFT JOIN левое соединение, при котором все записи из первой (левой)
таблицы включаются в результирующий набор, даже если во второй (правой)
таблице нет соответствующих им записей;
RIGHT JOIN правое соединение, при котором все записи из второй (правой)
таблицы включаются в результирующий набор, даже если в первой (левой) таблице
нет соответствующих им записей.
Например, предыдущий пример можно реализовать с использованием оператора
INNER JOIN следующим образом :
SELECT authors.author,titles.title,titles.yearpub,
Publishers.publisher
FROM ((titles INNER JOIN publishers ON
Titles.pub_id=publishers.pub_id)
INNER JOIN titleauthors ON
Itleauthors.title_id=titles.title_id)
INNER JOIN authors ON
Titleauthors.au_id=authors.au_id
WHERE titles.yearpub > 1996;
3. Вычисления внутри SELECT.
SQL позволяет выполнять различные арифметические операции над столбцами результирующего отношения. В конструкции <список_выбора> можно использовать константы, функции и их комбинации с арифметическими операциями и скобками. Например, чтобы узнать, сколько лет прошло с 1992 года (год принятия стандарта SQL-92) до публикации той или иной книги можно выполнить команду:
SELECT title, yearpub-1992 FROM titles WHERE yearpub > 1992;
В арифметических выражениях допускаются операции сложения (+), вычитания (-),
деления (/), умножения (*), а также различные функции (COS, SIN, ABS
абсолютное значение и т.д.).
В SQL также определены так называемые агрегатные функции, которые совершают действия над совокупностью одинаковых полей в группе записей. Среди них:
AVG(<имя поля>) - среднее по всем значениям данного поля
COUNT(<имя поля>) или COUNT (*) - число записей
MAX(<имя поля>) - максимальное из всех значений данного поля
MIN(<имя поля>) - минимальное из всех значений данного поля
SUM(<имя поля>) - сумма всех значений данного поля
Следует учитывать, что каждая агрегирующая функция возвращает единственное значение.
Примеры: определить дату публикации самой "древней" книги в нашей базе данных
SELECT MIN(yearpub) FROM titles;
SELECT COUNT (*) FROM titles ;
Область действия данных функции можно ограничить с помощью логического условия. Например, количество книг, выпущенных после 2000 года:
SELECT COUNT (*) FROM titles WHERE yearpub > 2000;
4. Функции для работы с датой
В MS Access предусмотрен целый набор встроенных функций дат и времени Перечислим некоторые из них:
Date () - текущая дата, т е сегодняшнее число, месяц и год;
D ау(дата) - извлекает из даты день, например дата - 12,09,97, число 12;
Мо nth (дата) - извлекает из даты месяц, например дата - 12,09,97, результат применения функции - число 9;
Уеаг(дата) - извлекает из даты год, например дата - 12-09,97, результат применения функции - число 97;
Weekday (дата) - извлекает из даты день недели в американской системе нумерации дней, а именно в примере - дата 12,09,97, результат применения функции - число 6, что соответствует пятнице,
DatePart (HHTepBan , дата) - здесь аргумент "интервал" - это сокращенное название нужного компонента даты, а дата - конкретное значение даты или имя поля с датой
Например:
DatePart (" H ",#12,09,97#) - день недели - 6, т е пятница,
DatePart (" HH ",#12,09,97#) - неделя года - 37,
DatePart (" K ",# 12,09,97#) - квартал года - 3
DatePart("a",#12,09,97#) - день -12,
DatePart("M",#12,09,97#) - месяц - 9, \ DatePart("rrrr",#12,09,97#) - год -1997
Пример запроса. Определить, сколько лет прошло с момента выхода статьи описавшей стандарт SQL (предположим, что название статьи ”Стандарт SQL ”)
SELECT Month(Date()-yearpub)
FROM titles INNER JOIN publishers ON
titles.pub_id = publishers.pub_id
WHERE publisher = "Стандарт SQL ";
5. Задание к лабораторной работе
Замечания по ходу выполнения лабораторной работы.
Для просмотра результата выполнения запросов необходимо чтобы в таблицах были внесены данные соответствующими сформулированным запросам. При этом данные в запросах (даты, фамилии, количество и т.п.) могут быть изменены по факту внесенных данных в БД.
При выполнении заданий лабораторной работы все вычисляемые поля заменять синонимами, используя опцию AS в предложении SELECT .
Например : SELECT COUNT (*) AS Количество _ строк FROM titles ;
Реализовать следующие запросы средствами SQL :
Найти заказы сделанные в январе.
Найти изделия, которые поставляются в количестве не меньше 10 , и не больше 100 .
Получить список изделий получаемых заказчиком “з-д «Красный луч»”, цена которых более 50 тыс. грн.
Сколько деталей «Болт» по всем заказам получил заказчик “з-д «Красный луч»”.
Определить наименования деталей заказанных в период с 6/10/ 97 по 10/10/97, которые не заказывал з-д «Красный луч».
Получить список наименований изделий, поставки которых превышают 10 тыс.
На какую сумму заказано деталей з-дом «Красный луч»
Какие заказчики заказывали деталь «Болт».
Определить среднее количество поставок детали «Болт» за 1997 год.
Найти заказчика, заказавшего самую дорогую деталь.
6. Контрольные вопросы
Какие предложения SELECT являются обязательными?
Что задает предложение WHERE?
Какие типы соединений (JOIN ) поддерживает инструкция SELECT ?
Какая последовательность предложений инструкции SELECT ?
В каком случае обязательно указывать имя таблицы перед именем поля?
Как формировать вычисляемые поля в SELECT ?
Можно ли соединять более двух таблиц операцией JOIN ?
Какой альтернативный синтаксис операции JOIN (с использованием WHERE ) можно использовать для корректного выполнения запроса?